开发了个 《一键导出 / 备份「有道云笔记」所有笔记》的脚本。主要原理是利用有道云笔记本身的接口。下面是根据正常用户操作逻辑,找到需要的接口,主要是登录和「下载」。
一、登录
登录的目的是获取 Cookie
1.1 找登录接口
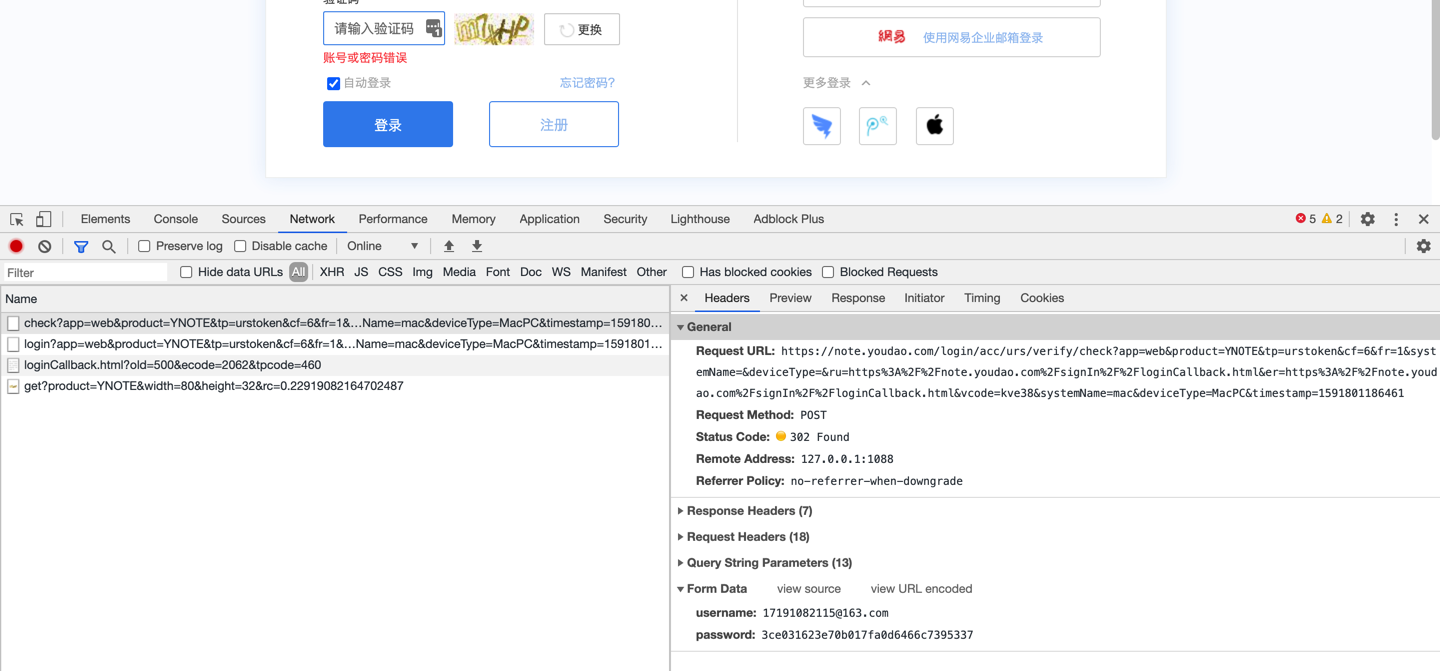
接口应该在登录时执行。使用错误密码测试,可得到登录 post 请求接口。注意过滤条件是 All
https://note.youdao.com/login/acc/urs/verify/?app=web&product=YNOTE&tp=urstoken&cf=6&fr=1&systemName=&deviceType=&ru= |
1.2 推导密码加密规则

本地测试使用同样错误密码用不同加密算法加密,看加密结果是否一致
发现使用 md5 加密
## Python3 |
1.3 找返回验证登录状态 Cookie 的接口
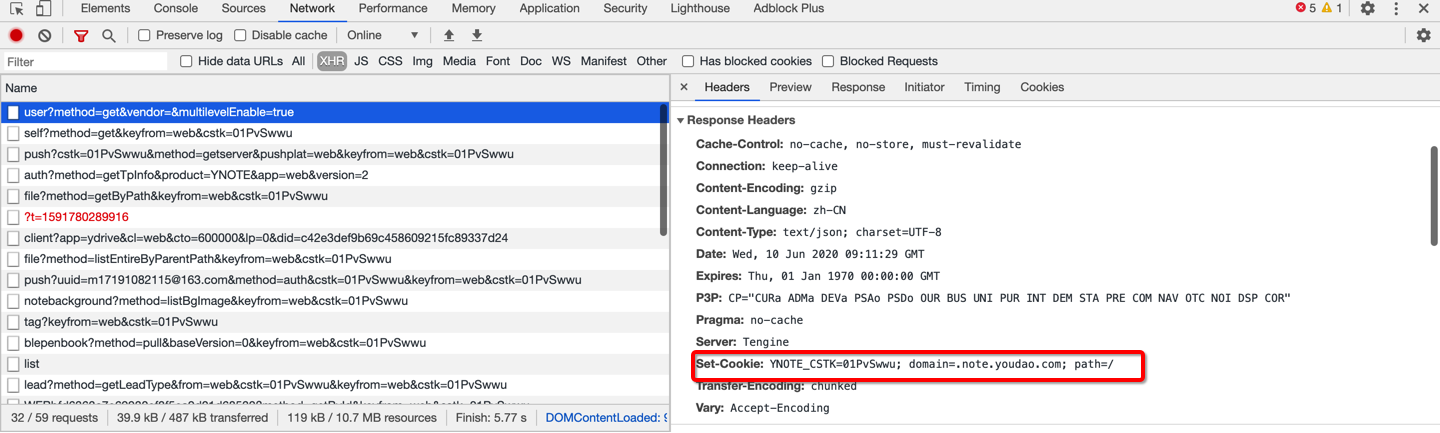
登录成功后,会返回验证登录状态的 Cookie。接口应该在登录成功后执行。发现跳转首页后第一个 XHR 接口中包含验证登录状态的 Cookie,YNOTE_CSTK
https://note.youdao.com/yws/mapi/user?method=get&multilevelEnable=true |
二、「下载」
2.1 找返回根目录 id 的接口
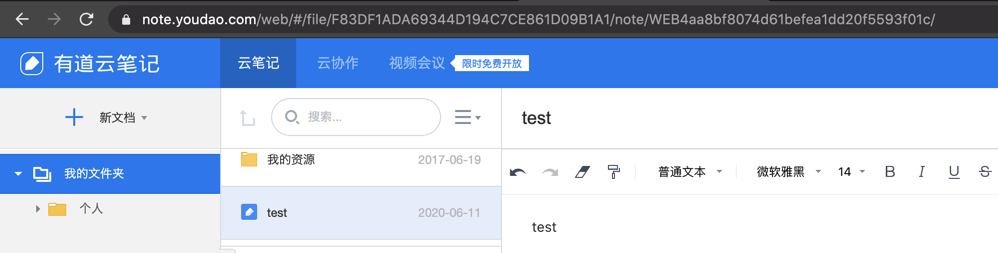
我们根据一个笔记 URL 可以看出,URL 里包含了父文件夹 id 和当前文件 id。「我的文件夹」下的 test.md 的 URL:
https://note.youdao.com/web/#/file/F83DF1ADA69344D194C7CE861D09B1A1/note/WEB4aa8bf8074d61befea1dd20f5593f01c/ |
「我的文件夹」 是根目录,它的 id 是 F83DF1ADA69344D194C7CE861D09B1A1,下面称它为 root_id。
我们推测,有道云笔记是设计是根据文件夹 id,获取文件夹下的所有文件信息(打开文件夹,可看到文件夹下的文件)。所以我们需要先得到 root_id。当登录成功后,跳转到首页时,应该有接口能得到 root_id。
测试发现下面接口返回值包含 root_id:
https://note.youdao.com/yws/api/personal/file?method=getByPath&keyfrom=web&cstk=01PvSwwu |
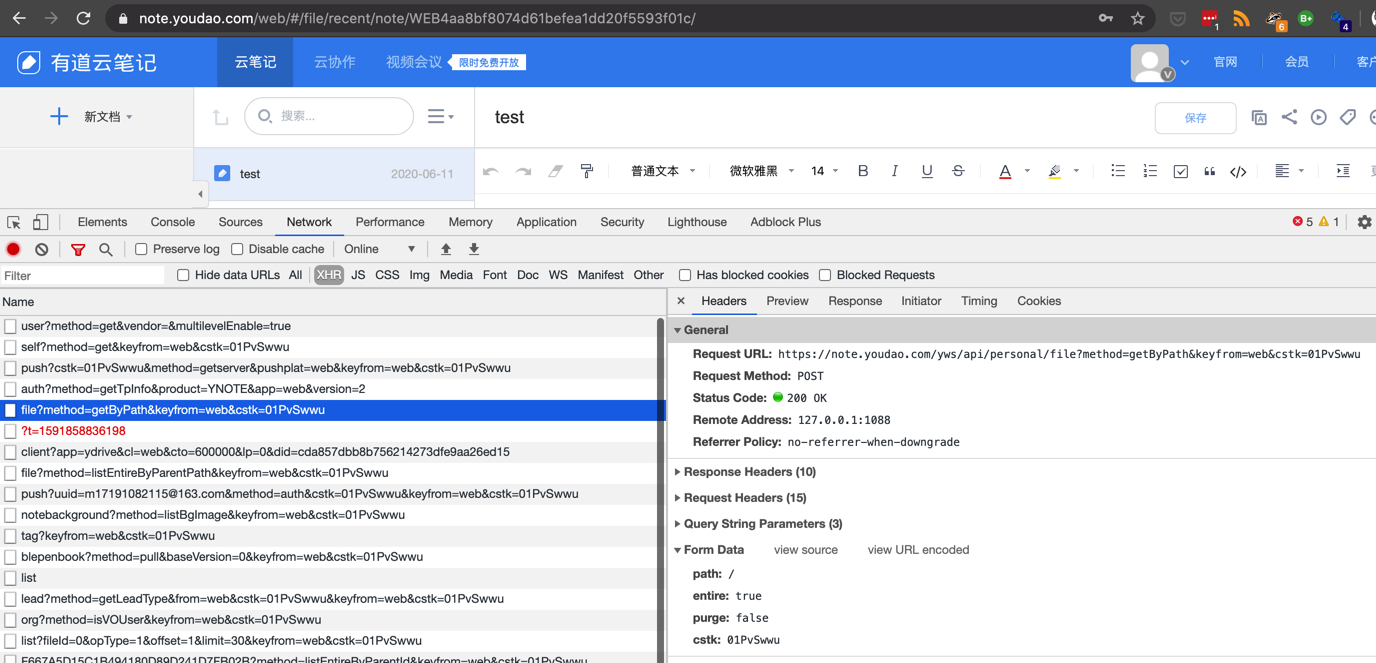
接口返回格式类似这样:
{ |
root_id = response.content['fileEntry']['id'] |
2.2 找获取目录下所有文件信息的接口
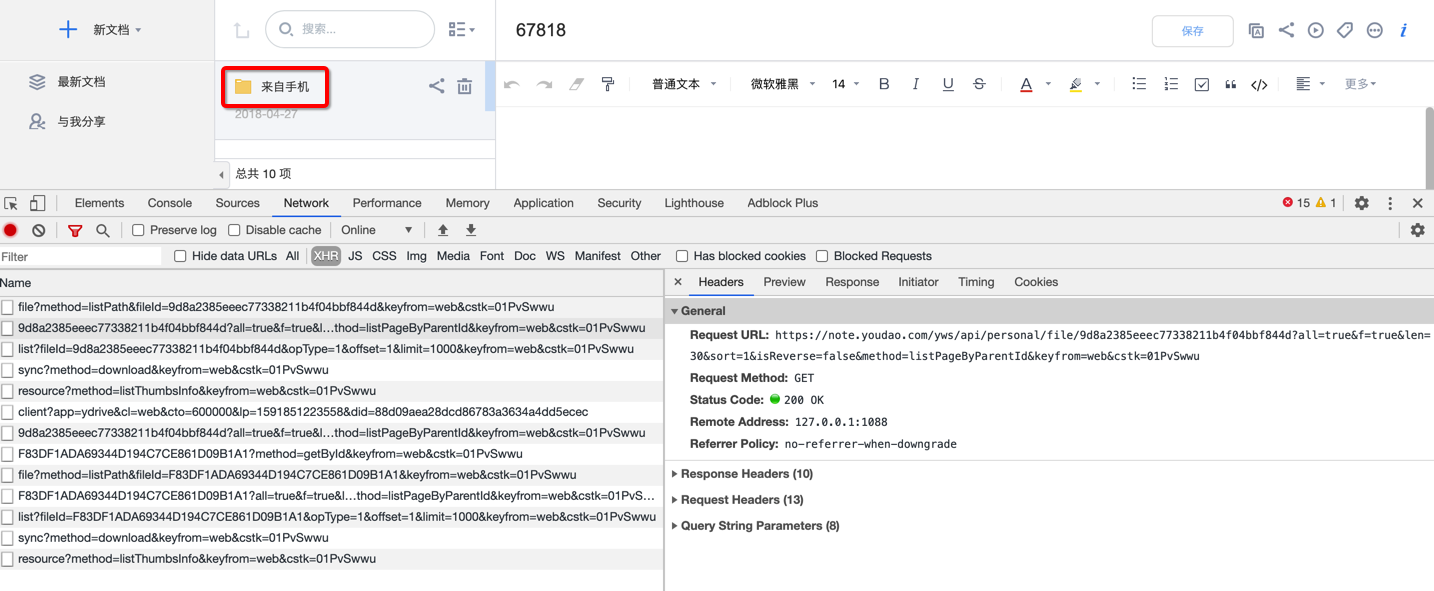
有了 root_id,需要找到根据 id 获取目录下所有文件信息的接口。
接口应该在打开文件夹时执行。点击某一个文件夹,测试发现包含当前目录所有文件信息的接口为:
https://note.youdao.com/yws/api/personal//9d8a2385eeec77338211b4f04bbf844d?all=true&f=true&len=30&sort=1&isReverse=false&method=listPageByParentId&keyfrom=web&cstk=01PvSwwu |
接口返回格式跟上面差不多,只是数量更多,属性多了 parentId(父文件夹 id)。
[ |
2.3 找到获取文件内容的接口
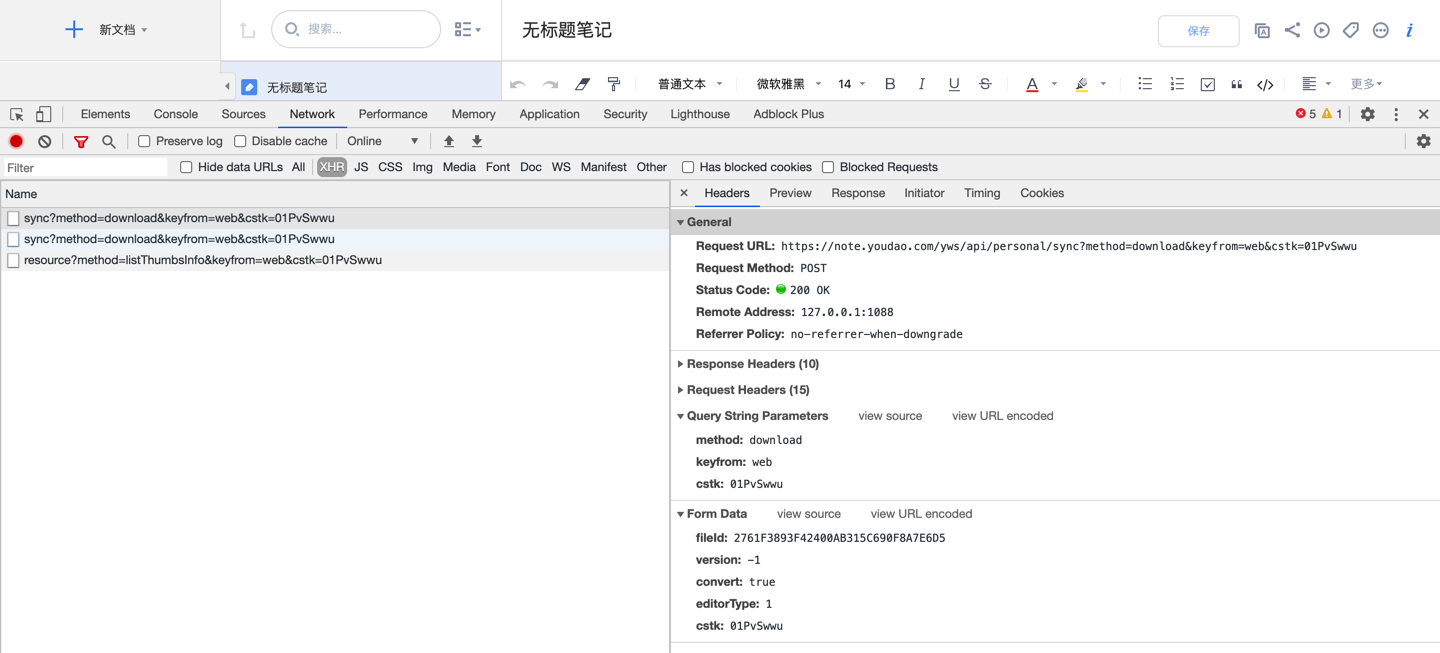
通过文件夹 id 得到了文件 id(fileId),需要找到根据 fileId 获取文件内容的接口。
接口应该在点击笔记标题得到笔记内容时执行。点击某一篇笔记标题,可以找到获取文件内容的接口:
https://note.youdao.com/yws/api/personal/sync?method=download&keyfrom=web&cstk=01PvSwwu |
三、模拟浏览器操作
3.1 设置请求头
随便哪个页面(如:首页 https://note.youdao.com/)可以看到请求头包含下面这些内容:

取一部分设置即可
class YoudaoNoteSession(requests.Session): |
3.2 模拟「进入网页版」

self.get('https://note.youdao.com/web/') |
点击「进入网页版」,会重定向到登录页面
3.3 模拟打开登录页

self.get('https://note.youdao.com/signIn/index.html?&callback=https%3A%2F%2Fnote.youdao.com%2Fweb%2F&from=web') |
跳转登录页后,要执行下面 3 个接口:
self.get('https://note.youdao.com/login/acc/pe/getsess?product=YNOTE&_=' + timestamp()) |
四、结语
根据找到的接口,模拟用户操作也有不少应用场景。除了开发像这种导出文件的脚本,可以开发一切你想自动化执行的操作。比方 cnblogs、juejin 发文章等。比较麻烦的就是像上面这样找接口了,可以先看看有没有人有过总结。
也可以利用一些浏览器的 API,如 Puppeteer,它提供一个真实的浏览器环境,可以真正模拟用户操作,不需要找到所有接口,只需要设置网页 url,以及设置需要操作的「按钮」属性。因为提供浏览器环境,它属于重量级操作。可以看看 ArtiPub 如何使用 Puppeteer。这种方式有点不好的地方就是平台可能改前端属性,需要注意更新。
全文完。
