
本文涉及剧透!
因为《周处除三害》充了 Netflix 的会员,拾起了原来因为漫画烂尾而没有看完的《进击的巨人》,看完发现动画版的结局不算烂尾,可以说《进击的巨人》是我看过的最好的动画剧集了。
此剧看完,我最大的疑问就是,艾伦为什么要发动地鸣,杀死墙外 4/5 的人类,因为在我看过的作品中,从没有作者将主角写得这么黑暗。虽然这个黑暗结果可以拉高作品的高度,使其更加不可超越。但一旦处理不好,就可能会烂尾,就像漫画的结尾一样。
本文涉及剧透!
因为《周处除三害》充了 Netflix 的会员,拾起了原来因为漫画烂尾而没有看完的《进击的巨人》,看完发现动画版的结局不算烂尾,可以说《进击的巨人》是我看过的最好的动画剧集了。
此剧看完,我最大的疑问就是,艾伦为什么要发动地鸣,杀死墙外 4/5 的人类,因为在我看过的作品中,从没有作者将主角写得这么黑暗。虽然这个黑暗结果可以拉高作品的高度,使其更加不可超越。但一旦处理不好,就可能会烂尾,就像漫画的结尾一样。
智能门锁是现代家庭中必不可少的设备,出门回家不用担心钥匙是否忘带,大大提高幸福指数
扫地机器人是现在家庭中一个很常见的清洁电器,购买前还是要做一下功能,看那款更适合自己,买了好用,物有所值。
住房舒适的 3 个关键:阳光、空气和水。净水器是现代家庭中必不可少的一项电器。我购买前在 BiliBili 上做了一些功课。
我做的功课主要来自于 BiliBili Wilson学长 的这个功略:燃气热水器应该如何选?
我做的功课主要来自于 BiliBili Wilson学长 的这个功略:【洗碗机选购】2023年各大品牌洗碗机到底应该如何选?
现代家庭的家庭用电一般都设计为多个回路,比如一般冰箱单独一个回路,在关闭家庭其它电源时冰箱能保持工作。有时一个回路会同时存在开关与插座,那么一个回路是如何实现开关、插座同时一起工作的。你是否有过同样的疑问,今天一起来了解一下吧。
我们先从简单的问题开始。电器插头插在插座上后为何就有电了?这是因为插座一个孔接到了零线,一个孔接到了火线,当插头插入插座时,火线和零线形成闭合电路,电流就能流过这个电路,电器就有电了。
昨晚上做梦,梦见学校的一个晚自习时间,几个小伙伴来唱歌,突然来了一个胖胖的学弟,开启麦霸模式,唱了一首歌,那饱满的情感,朴实真诚的歌词,掷地有声的演唱方式,瞬间变成了学校演唱会。
醒来后,我还隐隐那首歌记得最后一句好像是:「最重要的是,我从未改变过你」。
自从我设置了 Infuse + 阿里云盘 + NAS 观看影视,我媳妇追剧更方便了,但有个问题,当剧集还在连载时,最新剧集每次需要手动保存到自己阿里云盘。因为懒,试着搜了下有没有自动化工具,没想到还真有。
工具地址: https://github.com/adminpass/aliyundrive-subscribe
工具截图:
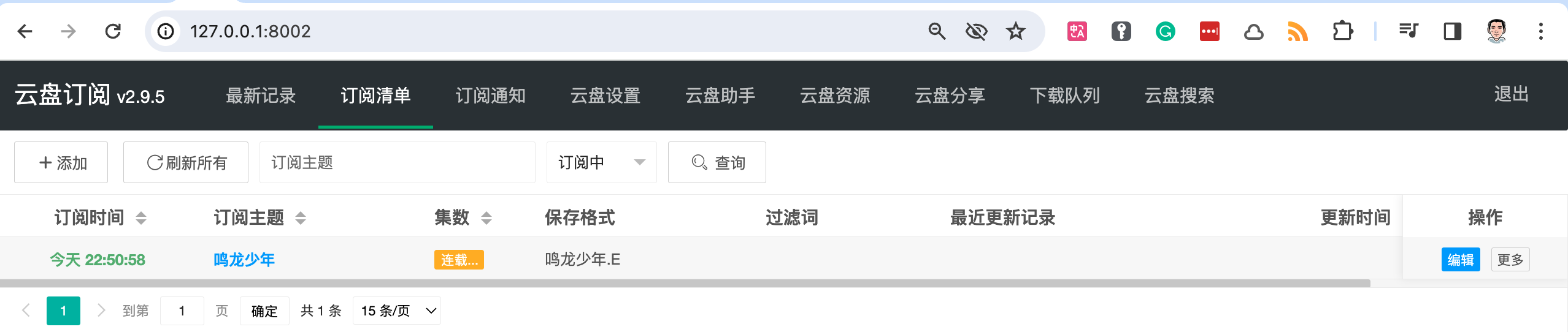
这是一个在 Docker 运行的本地 WEB 程序。启动并配置规则后,当云盘分享链接有更新剧集时,就会将更新剧集自动保存到你的云盘中,还提供资源搜索能力。
我开始装修时,对装修的先后顺序不清楚,特别是完全不知道什么时候应该购买什么东西。经历这次装修,发现只要知道这个东西什么时候用,用前买好就行。比如厨房烟道止逆阀,贴砖前买好就行。很多家电可以先不买,但需要确定购买型号,如洗碗机、冰箱、油烟机、马桶、扫地机器人等。这样水电和全屋定制就可以更好设计。大型家电可以活动时购买,推迟发货时间。以下我我装修材料购买 / 施工安装的顺序。
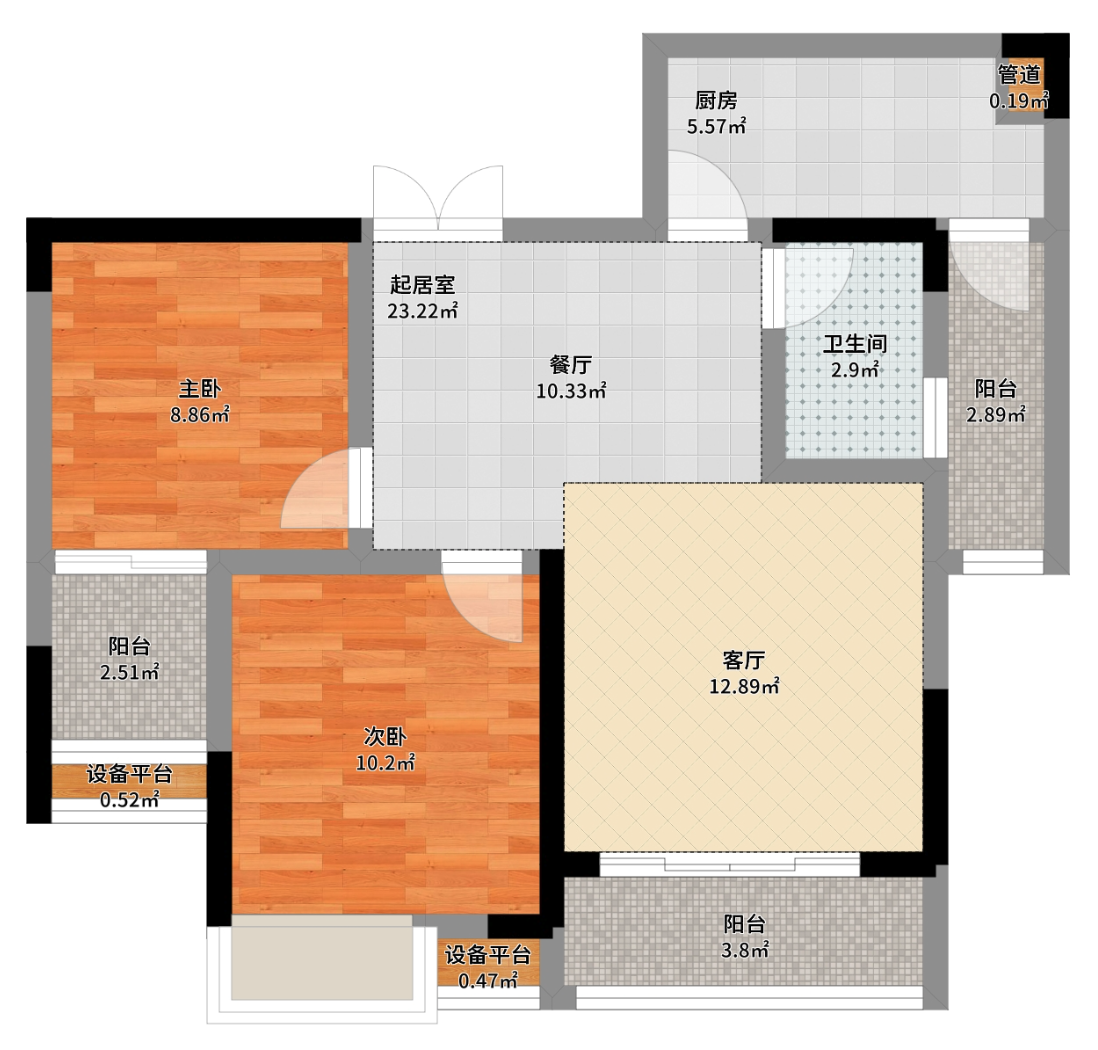
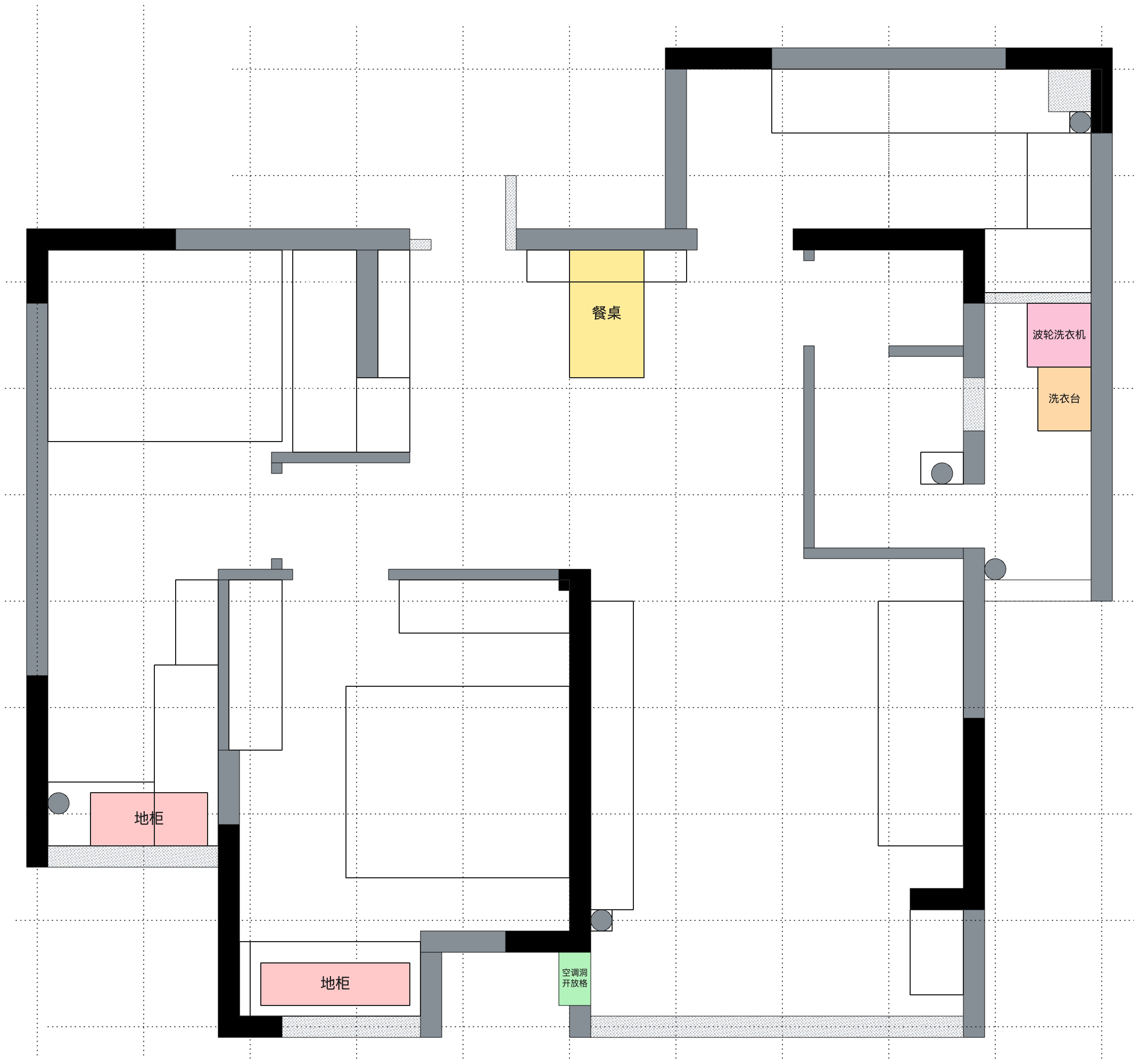
有点标题党了,但应该也差不多。前后设计对比图:
| 原始户型 | 最终户型 |
|---|---|
 |
 |
今年自己装修了一套房子,没有找装修公司和团队,所有事亲力亲为,操了很多心,花了不少钱,也费了不少时间,现在已经住进来了一段时间了,有一些装修经验,现分享一下。
需要护照,我是参考「 数字牧民LC」教程开户的,内容比较详细,按教程步骤操作就行。
我运气比较好,开户没有遇到什么问题,秒开。说说我开户的经验。
在上一篇文章中写到我搭建了 NAS,但没有折腾外网访问功能。这篇文章就写一下我如何实现 NAS 外网访问。
外部设备要访问家里局域网中设备,最好局域网有一个公网 IP,如果没有公网 IP,就只能使用内网穿透的方式。
我日常没有什么大容量储存需求,连硬盘也没有买,一些需要数据备份与远程同步的场景我使用 iCloud,200G 的空间也够用了。前些天电脑突然启动不了,因为没有使用「时间机器」备份系统,只能重装系统,虽然数据基本没有丢失,但软件安装、软件配置等也断断续续搞了几天。不想再次出现这个问题,时间机器备份得马上安排上,因为时间机器需要外置硬盘,现在也出现一些大容量存储需求,索性一步到位,整个 NAS。
NAS,全名 Network Attached Storage,网络附加存储。硬盘也叫 DAS(Direct Attached Storage ),直接附加存储。DAS 是通过数据线直接连接在电脑上使用,而 NAS 是可以不用数据线,直接通过网络使用的 DAS。
公司项目使用 Spirng Cloud Alibaba,使用 Nacos 注册中心,部署在华为云的 CCE(基于 K8s)中。为节约资源,开发测试环境的服务只部署了一个节点。这时出现一个问题:每次节点部署,系统就会出现服务短暂不可用的情况。
同一个局域网内,一个设备翻墙,其他设备不安装翻墙软件,直接借助其网络翻墙的方式,一般有 2 种:
我这样使用 ChatGPT: